Mar 31, 2026
How Context Graphs Are Replacing RAG in Private Equity

Pablo Rios

When a senior partner leaves a private equity firm, they don't just take their Rolodex. They take the institutional memory of why the firm passed on 30 deals, which LP relationships were warming toward a commitment, and what diligence patterns flagged risk before anyone wrote them down. The reasoning that shaped hundreds of millions in capital allocation walks out the door, and no system of record captured any of it.
This is the decision trace problem. Private equity generates enormous volumes of contextual reasoning: investment committee memos, due diligence questionnaires, deal screening notes, portfolio company reviews. But the infrastructure built to manage this information treats it as documents to be filed, not decisions to be learned from.
Foundation Capital's thesis on context graphs frames this as the "two clocks" problem. The state clock tracks what's true right now: Sarah is a VP, the deal closed at $500K, Fund III is in deployment. The event clock tracks what happened, in what order, with what reasoning, and what was true at the time the decision was made. We've built trillion-dollar infrastructure for the state clock. Almost nothing for the event clock.
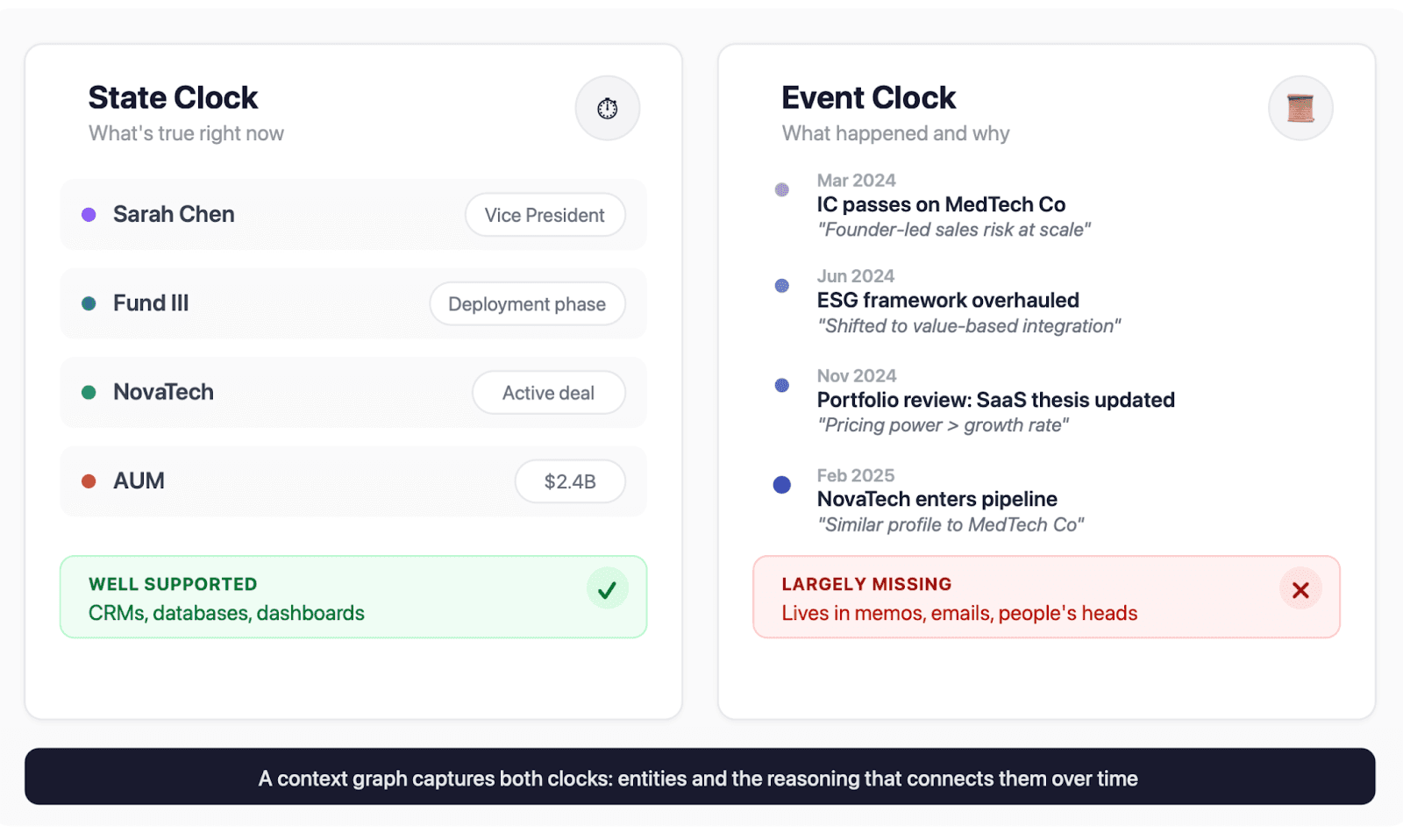
A context graph captures both clocks. It models entities and their relationships, but also preserves why things happened: the reasoning, the evidence weighed, the alternatives considered. Not just what your firm has seen, but the decision logic that connects it all. Foundation Capital describes the opportunity as infrastructure that makes decision traces searchable, so precedent becomes a queryable asset rather than institutional memory that walks out the door.
Why RAG Fails for Private Markets
Retrieval-augmented generation, the pattern most AI products use today, treats documents as interchangeable chunks of text. Embed them, store them in a vector database, retrieve the most similar text when a user asks a question, feed them to a language model. This works well when documents are self-contained: a knowledge base article, a product manual, a FAQ.
Private markets break this assumption in three ways.
First, relationships encode meaning. A due diligence memo matters because of which company it evaluates, which deal stage it was produced during, and which investment professional wrote it. Strip that context and you have text. Preserve it and you have institutional knowledge.
Second, temporal validity varies across document types. A fund's strategy overview from 2024 may still be accurate. But a DDQ response about the firm's approach to ESG (Environmental, Social, and Governance) integration from the same year could describe a framework the firm has since overhauled. An LP asking "How does your firm integrate ESG factors into diligence?" will get a confident, well-written, semantically perfect answer from 2024, and it will be wrong. Nothing in the query signals that recency matters, but it does. The retrieval system needs to understand time, not just similarity.
Third, data resolution is a prerequisite for retrieval. When a user asks about "Acme Corp," they might mean Acme Corporation, Acme Holdings, or Acme Capital Partners. Before you can retrieve relevant documents, you need to resolve the entity. In private markets, there's no ticker symbol, no CUSIP. You need fuzzy matching, disambiguation, and often human confirmation.
Recent research from the University of Illinois quantifies why getting context wrong is worse than having less context. One study found that even when models retrieve all relevant information perfectly, answer quality still degrades 14% to 85% as more context is stuffed into the prompt. Another showed that adding more retrieved documents actually makes answers worse once semantically similar but incorrect passages enter the context window. In entity-rich domains where relationships carry meaning, "incorrect" isn't just topically off. It's contextually wrong. A perfectly relevant document about the wrong Acme is worse than no document at all.
RAG's fundamental limitation is that it retrieves text. What private markets need is infrastructure that retrieves entities, their relationships, and the reasoning that connects them.
What a Context Graph Actually Looks Like

Metal models firm history as interconnected data points in the graph, not isolated documents. Companies, documents, deals, people, expert calls, screenings, discussion threads: these are first-class data types with relationships connecting them.
The core insight is that the same data needs to be findable through different lenses. When an analyst types "Acme," the system runs a name-matching search to locate the relevant data. When they ask "find companies like Acme," the system uses a different representation of the same data, one tuned for business similarity rather than name matching. These aren't different queries against the same index. They're fundamentally different retrieval operations that happen to involve the same piece of information.
When results come back, they don't arrive as a flat list of text. Every result carries its data type: this is a Deal, this is a Person, this is an Activity, this is a Document excerpt. The AI knows what kind of thing each piece of context represents, which lets it reason across data types rather than treating everything as undifferentiated text.
Agents as the Orchestration Layer
The reason a context graph can answer complex questions is that AI agents orchestrate the retrieval, not a single query. Ask:
What companies similar to NovaTech have we passed on?
A standard RAG system would reference that sentence, find similar text, and hope for the best. Metal's agent layer does something fundamentally different.
First, the system resolves NovaTech as an entity, using name matching and, when needed, LLM-based disambiguation to pick the right one from multiple candidates. It then builds a relationship summary: deals associated with that company, people involved, relevant documents, activity history. With the entity resolved and its context mapped, the agent selects the next retrieval operation: find similar companies by sector and business characteristics, then query deals for those companies filtered by status.
Five or six distinct retrieval operations fire across this sequence, each targeting a different entity type with a different ranking strategy, assembling the results into a single coherent answer with every source cited and traceable. This is closer to how an analyst actually builds a view on a question than anything a single retrieval call can produce.
Time as a First-Class Signal
One of the hardest problems in data-aware retrieval is temporal ranking. In private equity, the right answer to a question isn't always the most comprehensive one. It's often the most recent one.
Consider a deal team evaluating a healthcare services company. They ask:
What has our firm's experience been with physician practice management platforms?
The system finds three IC memos spanning five years. The 2021 memo describes a market with fragmented reimbursement and regulatory uncertainty. The 2023 memo reflects a post-COVID shift toward value-based care models. The 2025 memo captures the firm's updated thesis after two portfolio companies in the space.
A standard retrieval system would rank these by semantic similarity to the query, and the 2021 memo, which has the most detailed market analysis, might score highest. But the deal team needs the most recent institutional view, not the most comprehensive historical one. The firm's thinking evolved, and the 2025 memo supersedes the earlier analysis even though it's shorter and less detailed.
Metal solves this by blending semantic relevance with temporal recency in the ranking function itself. Documents lose a small fraction of their temporal weight each day, so a 100-day-old answer retains meaningful relevance but yields to a fresher response on the same topic. The balance between "most relevant" and "most recent" emerged from testing against real investor workflows, not from a theoretical model of information decay.
This matters across every document type a PE firm produces. IC memos, portfolio reviews, DDQ answer banks, market assessments: in every case, the temporal context of a document is as important as its semantic content. A context graph treats time as a ranking signal, not just metadata.
Better Context Beats Better Models
There's a natural temptation to focus on which AI model is smartest. But the research points in a different direction: the quality of what goes into the model matters more than the sophistication of the model itself.
A context graph ensures that when your team asks a question, the system sees the right entities, the right relationships, and the right temporal context, not just the most similar text. When a deal team is building conviction on a B2B software company, agents can traverse your firm's own history with similar businesses, surface the outcomes of those investments, and retrieve the reasoning your IC applied at the time.
The industry is starting to call this discipline context engineering: the practice of assembling exactly the right information for an AI system to reason over. The teams that will win in enterprise AI are not the ones with access to the largest language models. They are the ones that build the infrastructure to get context engineering right, entity-aware, temporally valid, relationship-rich, and deliver it to models that can reason over it.
That infrastructure is what we're calling a context graph or knowledge graph. And for private equity, where conviction is built on pattern recognition across decades of institutional experience, it may be the most important piece of AI infrastructure a firm can invest in.

